Robust trajectory design and guidance for far-range rendezvous using reinforcement learning with safety and observability considerations
Overview
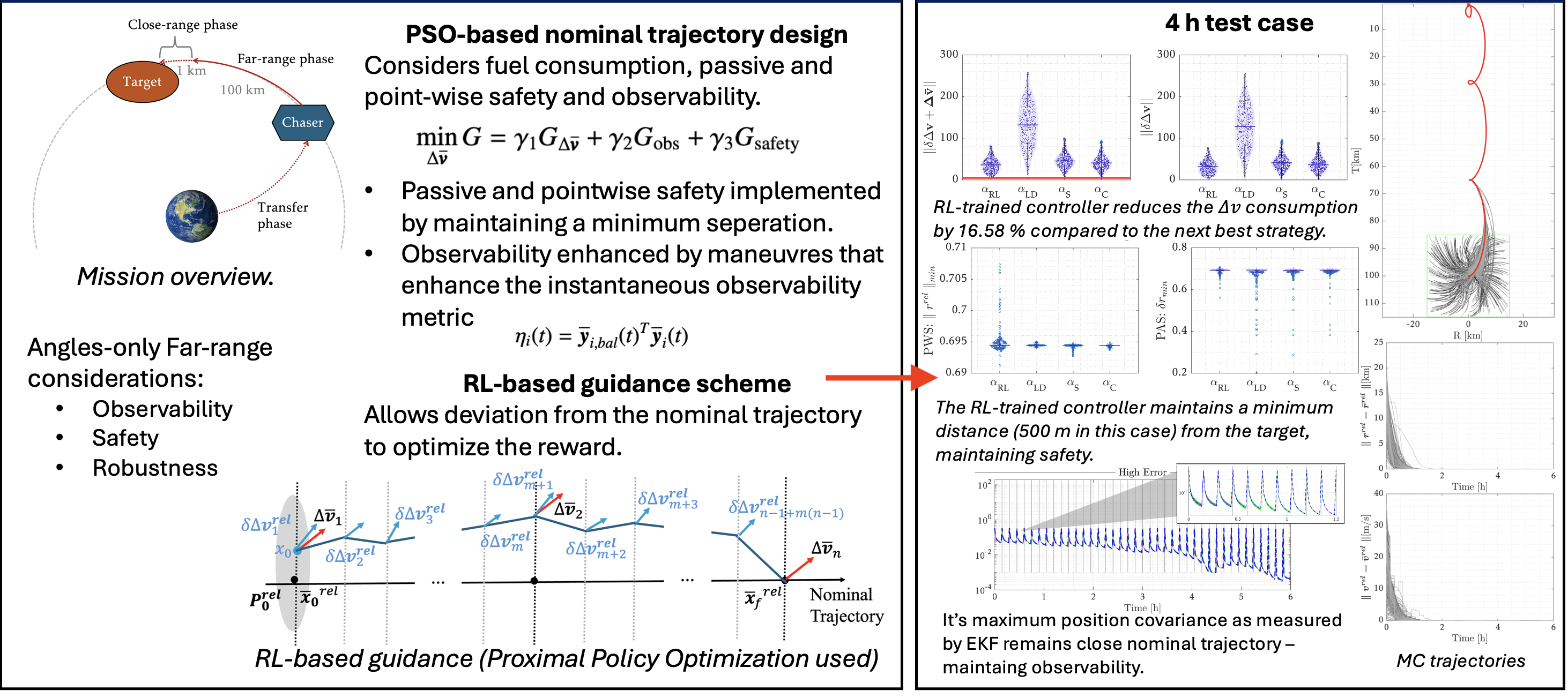
This work addresses far-range rendezvous under angles-only navigation by combining nominal trajectory planning under fuel, safety, and observability constraints with a reinforcement-learning guidance layer trained under realistic uncertainties. The goal of the RL guidance is to maintain safety and observability while minimizing fuel consumption during execution.
Motivation
Far-range rendezvous demands robust execution in the presence of initial state dispersion and actuation errors. With angles-only measurements, observability—particularly range—can degrade unless the guidance policy actively manages relative motion geometry. At the same time, safety constraints (e.g., keep-out regions and passive safety) must be respected throughout the approach.
Method
The approach is a two-stage pipeline: nominal impulsive trajectory design that explicitly trades fuel, observability, and safety, followed by an RL-guided execution layer that selects a contraction level and solves a small convex problem to compute guidance impulses online.
Stage 1 — Nominal trajectory planning
We select a sequence of impulsive manoeuvres \(\{\Delta {\mathbf{v}}_i\}_{i=1}^{n}\) by minimising a composite objective:
Total impulse magnitude over the plan:
The final impulse is computed via the Lambert's method to ensure the terminal target state is reached.
Observability is encouraged by shaping the measurement profile. The score used is the alignment between ballistic and forced measurement directions:
Blue: \({\mathbf{y}}(t)\). Black: \({\mathbf{y}}_{\mathrm{bal}}(t)\).
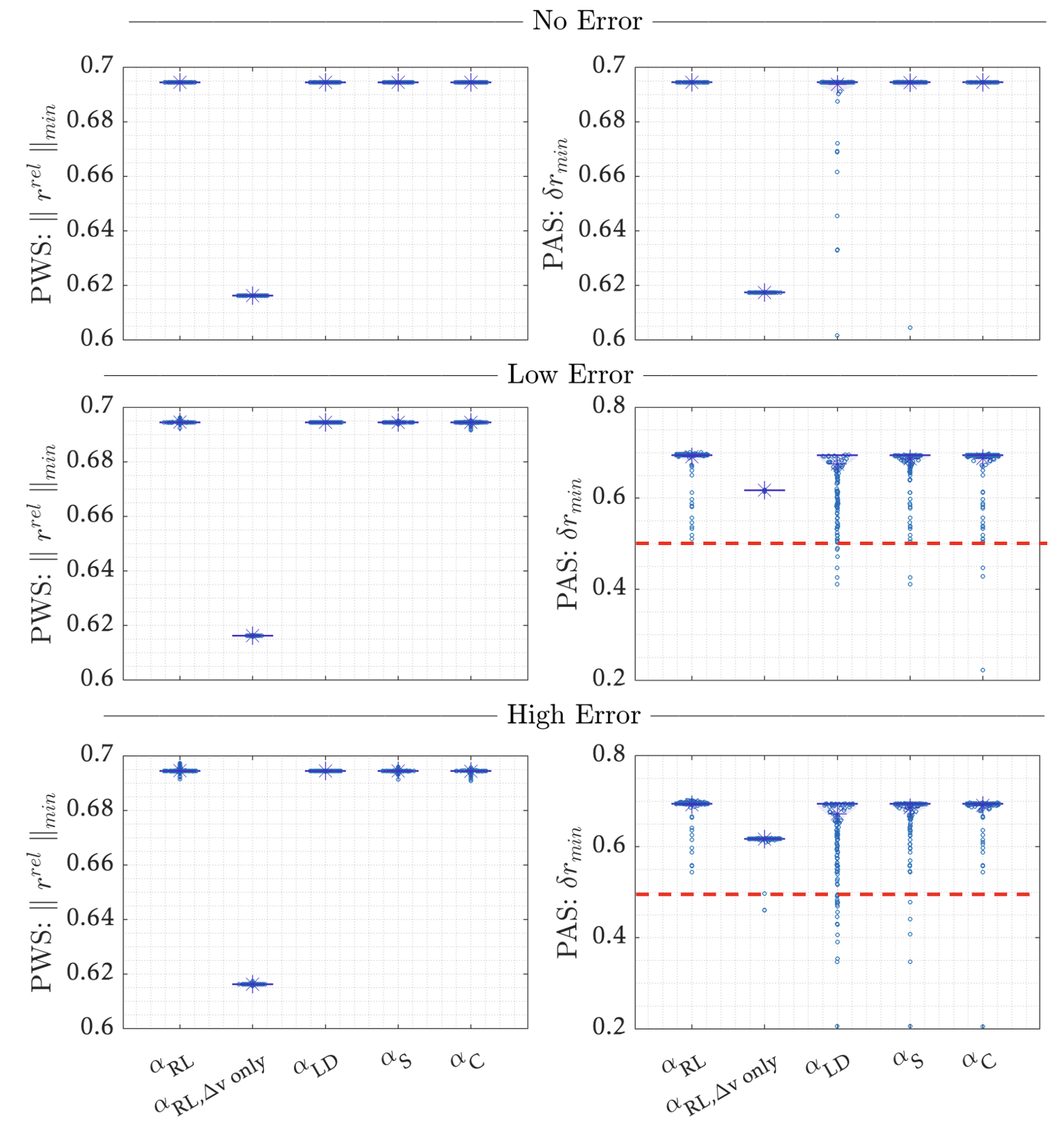
Point-wise safety (PWS) and passive safety (PAS) are encoded via penalties:
where \(\mathbf{r}^{\mathrm{rel}}(t)\) is the relative position (so \(\|\mathbf{r}^{\mathrm{rel}}(t)\|_2\) is the relative distance), and \(\delta r_{\mathrm{PAS}}^{\min}(t)\) is the minimum passive separation distance.
Stage 2 — RL guidance + convex optimisation
At each guidance update \(k\), a PPO policy outputs a contraction parameter \(\alpha_k\) that limits how quickly the deviation from the nominal plan must shrink. Given \(\alpha_k\), we compute the minimum-effort impulse by solving a small convex programme.
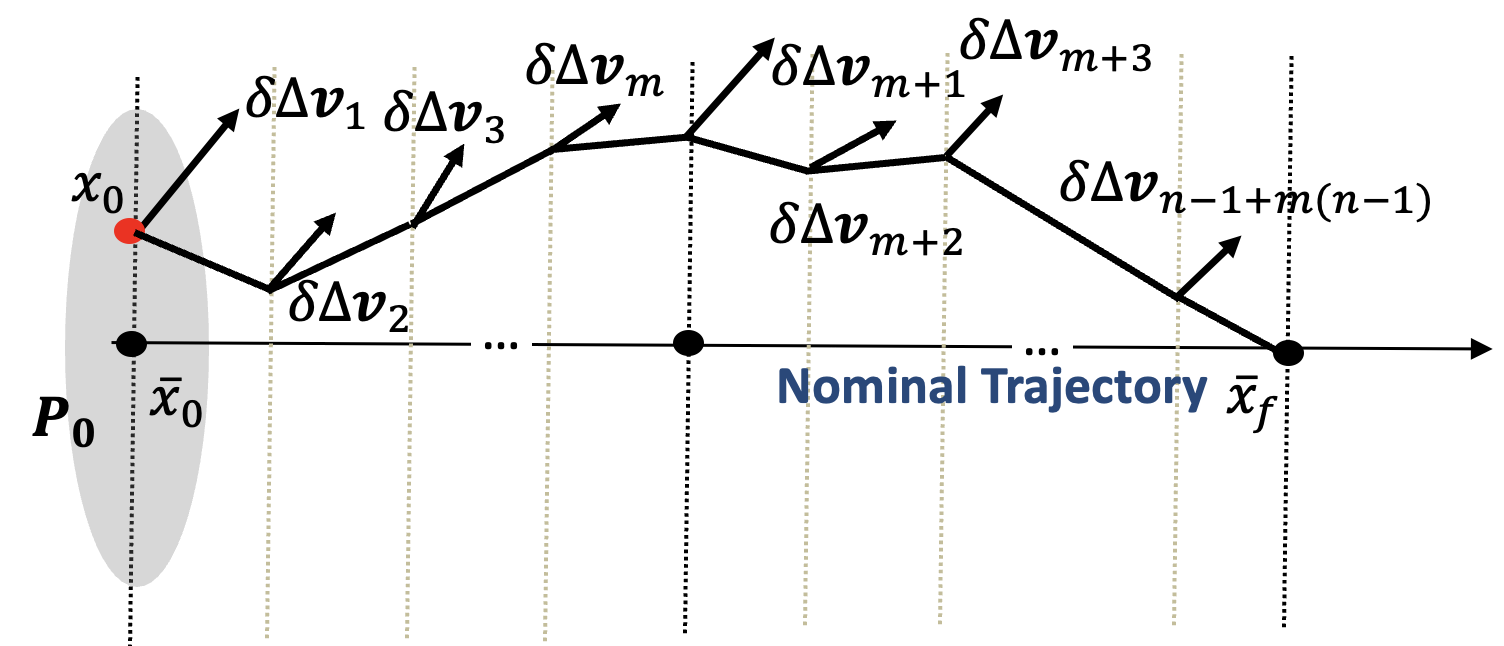
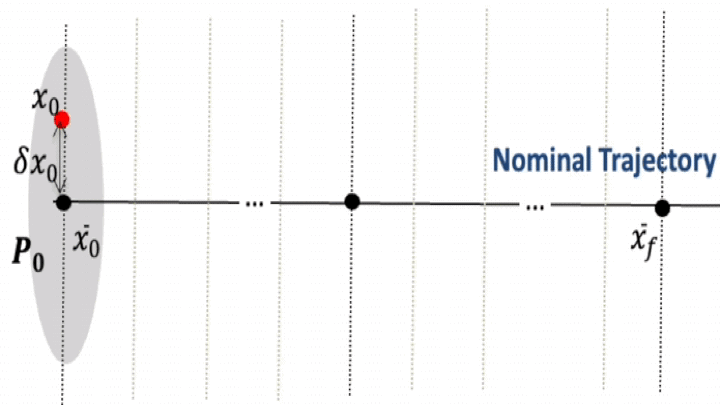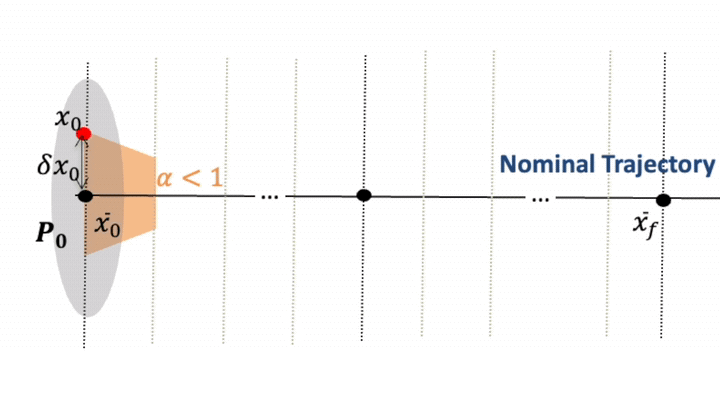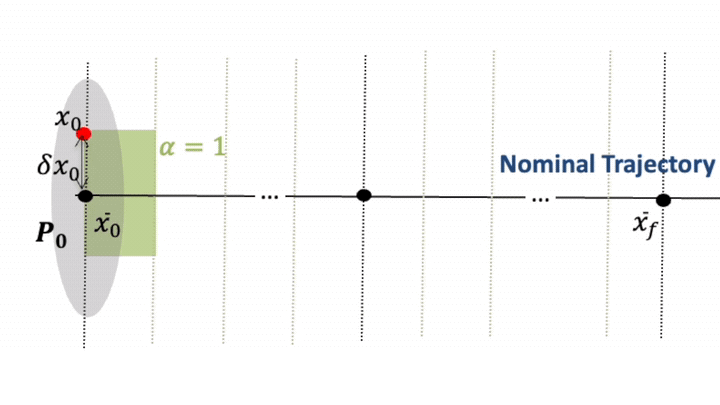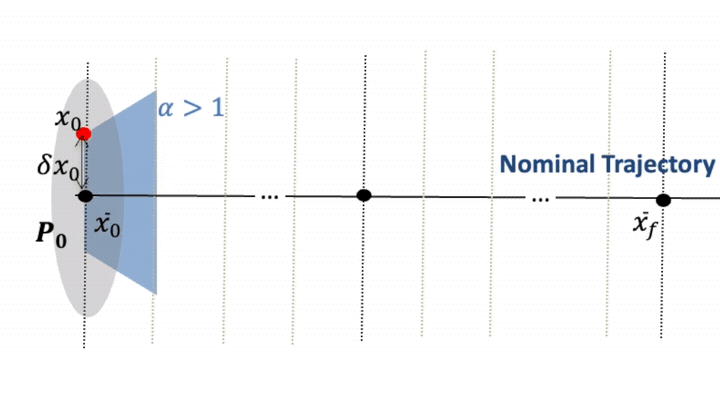
Training is performed in a stochastic environment (initial state errors, thrust errors), with a reward that discourages \(\Delta v\), constraint violations, and poor observability, while encouraging convergence to the terminal set.
Results
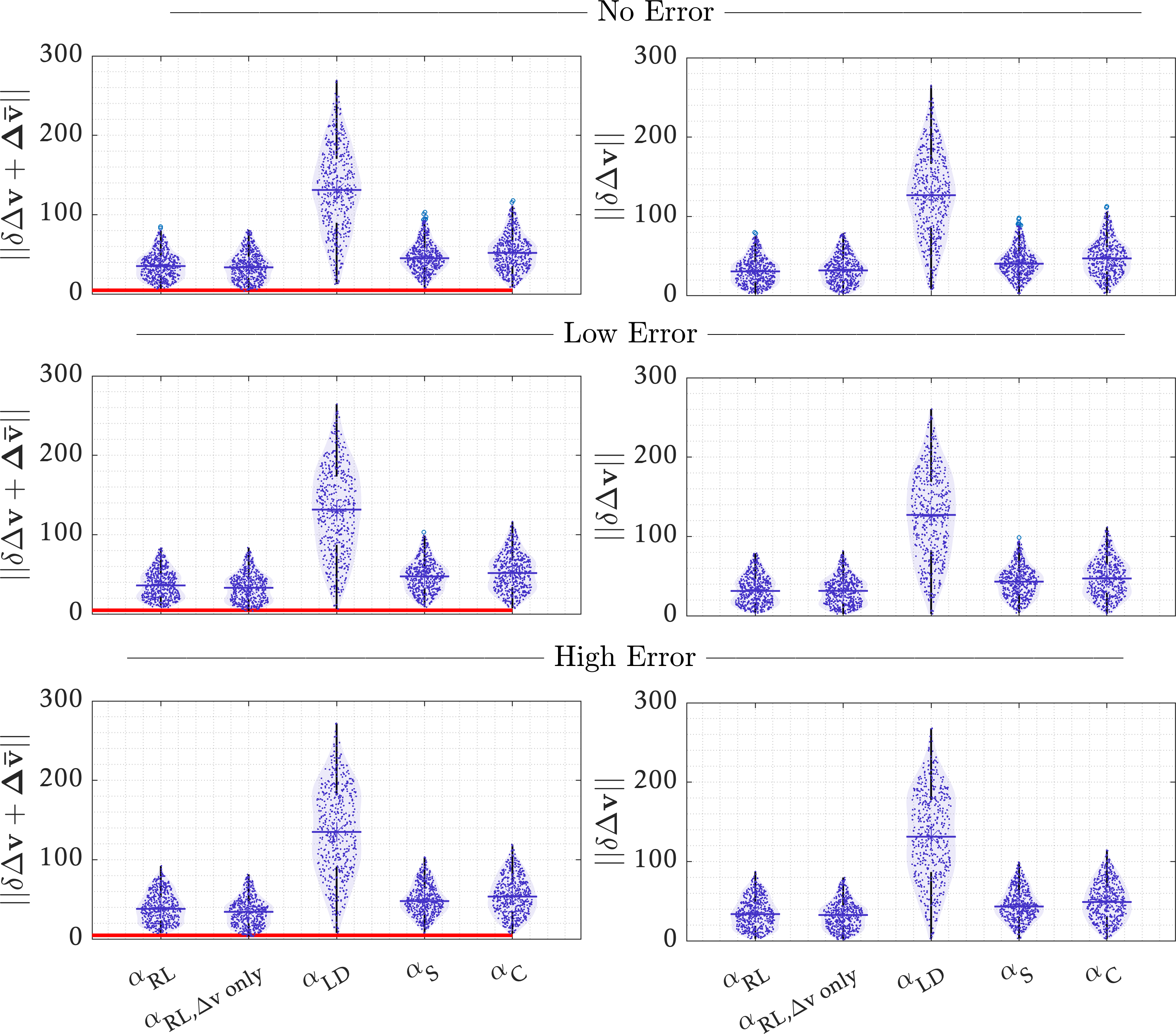
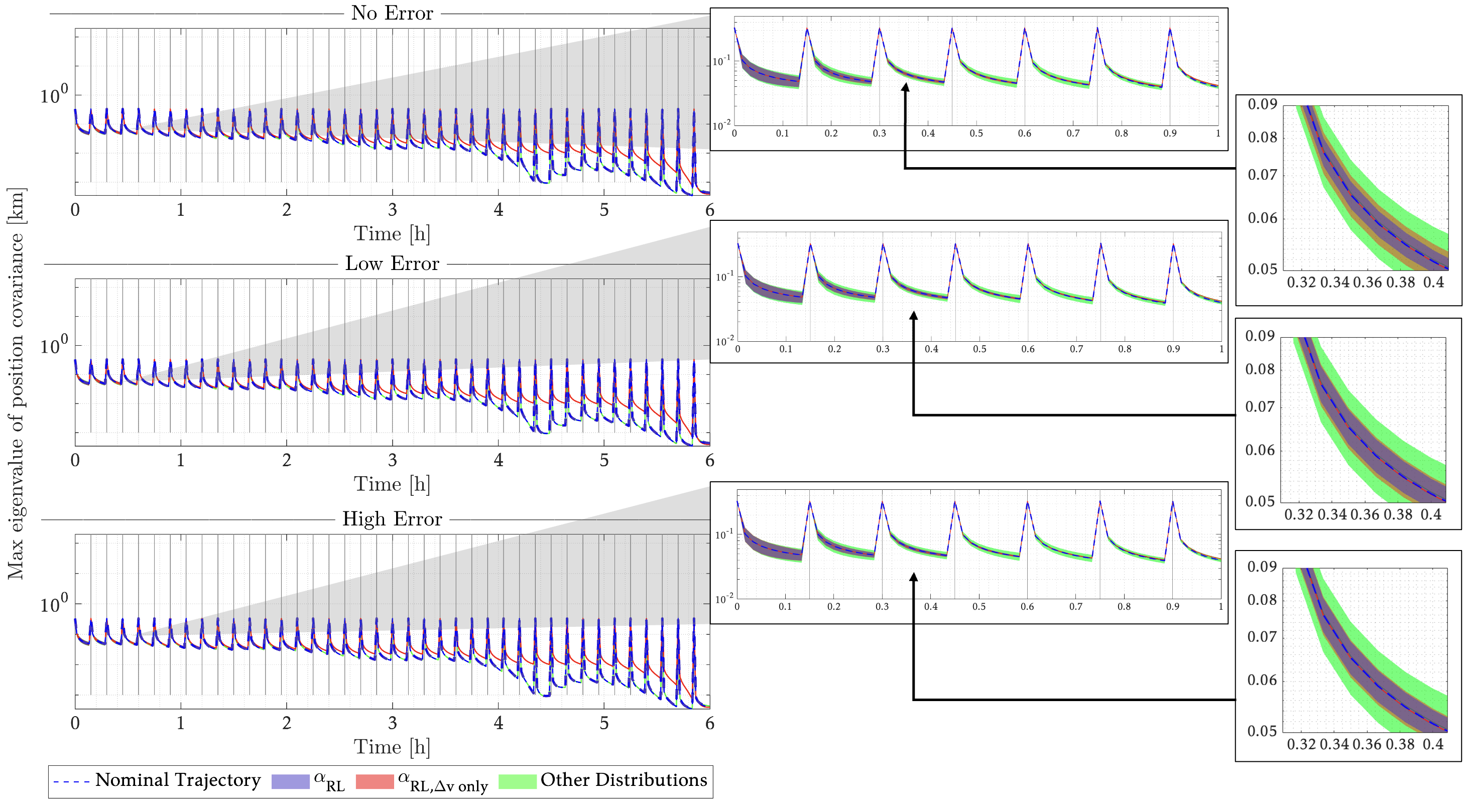
Performance is evaluated using 500-sample Monte Carlo simulations under three thrust-error regimes (no / low / high). We report total \(\Delta v\) consumption, safety with a 500 m keep-out zone (KOZ), and observability using the EKF maximum position-covariance eigenvalue metric.
Evaluation setup
We benchmark the RL-trained contraction parameter \(\alpha_{RL}\) against fixed and heuristic contraction schedules, and evaluate robustness under zero-mean thrust errors applied to each commanded impulse. Reported “error levels” are standard deviations (bias \(=0\)).
| Method | Definition | Notes |
|---|---|---|
| \(\alpha_{RL}\) | \(\alpha\) from PPO policy | Learned online contraction level |
| \(\alpha_{LD}\) | \[ \alpha_{LD,j}=1-\frac{t_j-t_0}{t_f-t_0} \] | Linearly decreasing schedule |
| \(\alpha_C\) | \(\alpha_C = 0\) | Constant contraction |
| \(\alpha_S\) | \[ \alpha_S=\arg\min_{\alpha}\left(\sum_{k=1}^{12}\sum_{j=1}^{j_{\mathrm{end}}} R_j\right) \] | Sigma-point optimised \(\alpha\) |
| Simulation | \(\sigma_{\Delta v}\) (%) | \(\sigma_{\beta}\) (deg) | \(\sigma_{\gamma}\) (deg) |
|---|---|---|---|
| No error | 0 | 0 | 0 |
| Low error | 2 | 1 | 1 |
| High error | 4 | 2 | 2 |
More figures (observability and terminal error)
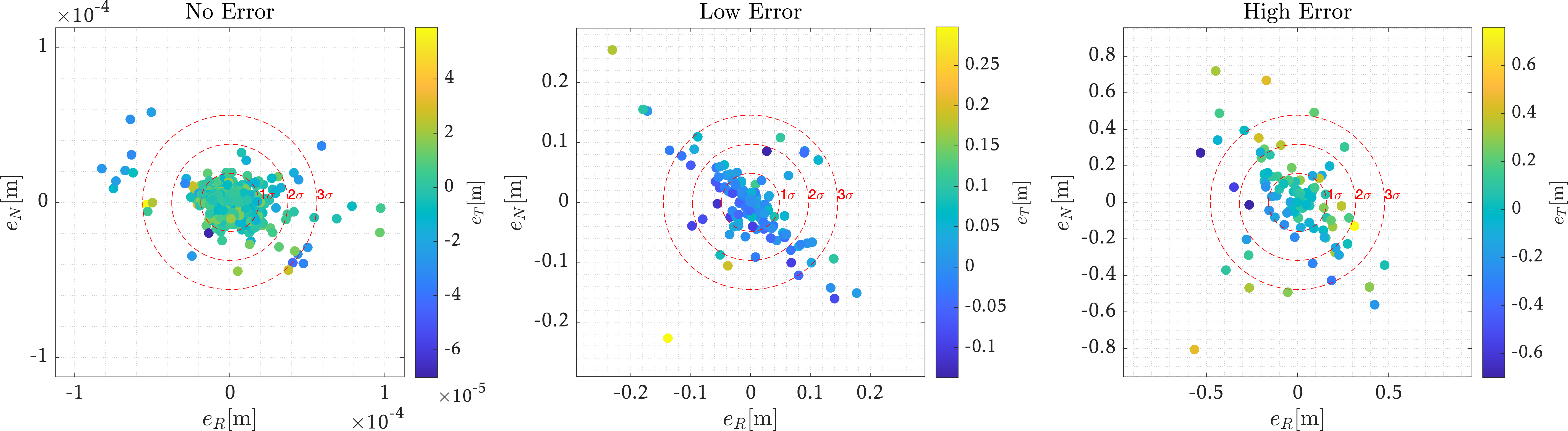
- No error: \(37.07 \pm 17.41\) m/s
- Low error: \(37.52 \pm 18.15\) m/s
- High error: \(39.90 \pm 19.04\) m/s
- \(\alpha_{RL}\) maintains KOZ compliance across all error regimes in the Monte Carlo runs.
- Under PAS (missed-impulse) evaluation, only \(\alpha_{RL}\) avoids KOZ breaches across all error cases.
- \(\alpha_{RL}\) trajectories keep covariance close to the nominal profile and converge back within \(\sim\)2 h.
- Non-RL baselines show broader covariance variation, often worse than the nominal trajectory.
BibTeX
@article{WIJAYATUNGA2025109996,
title = {Robust trajectory design and guidance for far-range rendezvous using reinforcement learning with safety and observability considerations},
journal = {Aerospace Science and Technology},
volume = {159},
pages = {109996},
year = {2025},
issn = {1270-9638},
doi = {https://doi.org/10.1016/j.ast.2025.109996},
author = {Minduli Charithma Wijayatunga and Roberto Armellin and Harry Holt}}